
Il y a quelques semaines, j’ai eu l’occasion de mettre en place le déploiement d’un gros e-commerce sur AWS. Je déploie des applications métiers et de l’e-commerce depuis de nombreuses années sur des VPS / Dédiés ou des infra PaaS pour l’autoscaling, mais je n’ai encore jamais eu l’occasion de travailler sur AWS pour la simple et bonne raison que ce n’est souvent pas « utile ».
Là, le client est déjà sur AWS, son infra VPC (Virtual Private Cloud) fonctionne parfaitement, tout est bien rodé et infogéré par un prestataire spécialisé dans ce domaine. Cependant, pour plusieurs raisons (non évoquées ici), le déploiement ne fonctionne plus.
Choix de la solution Ansistrano
J’ai fait le choix il y a des années d’utiliser Capistrano pour mes déploiements, la solution est rodée dans mes process et dans les process de mon équipe. On a des plugins, des tâches customs de rapatriement de données, etc., on l’utilise vraiment tous les jours sur environs 95% de nos projets. Malheureusement, un seul bémol pour AWS, l’inventaire dynamique n’est pas géré par Capistrano.
Effectivement, dans le cadre de ce projet assez costaud, la preprod et la prod sont paramétrés avec de l’ASG. C’est quoi l’ASG ? Auto Scalling Group, en gros si la charge devient importante sur l’infra, l’infra va automatiquement se redimensionner pour tenir. Les serveurs applicatifs vont donc « pop » et « depop », et c’est là que ça devient compliqué de déployer sans savoir combien de serveurs sont actifs et surtout sans forcément connaitre leurs IPs.
C’est là que Ansistrano devient intéressant (de mon point de vue). Ansistrano est grosso modo un portage de Capistrano sur Ansible, et qui profite intrinsèquement de tout l’écosystème de Ansible. Nous, ce qui nous intéresse ici est bien sûr son inventaire dynamique. Lors du déploiement, il est capable de lister toutes les instances et leurs groupes sans aucune action manuelle.
Architecture et mode de fonctionnement
Le déploiement est composé de deux “entités” distinctes sur git.
1. E-commerce
- Dépôt de code
- CI/CD
- Build du code
2. Ansistrano
- Déploiement
- Rollback
Ansistrano est configuré en tant que « submodule » git sur le dépôt de code du site e-commerce. Les tâches de déploiement et de rollback sont disponibles et peuvent être lancées depuis gitlab-ci.
Le dépôt Ansistrano peut également être utilisé « seul » pour déployer la dernière version. C’est ce mode de fonctionnement qui est utilisé lors de l’autoscalling pour provisionner les machines avec l’application.
Workflow de déploiement
Build
- Build de l’applicatif
- Push sur un bucket S3 du code sous forme de tarball
- Définition de la dernière version dans un fichier RELEASE a la racine du S3
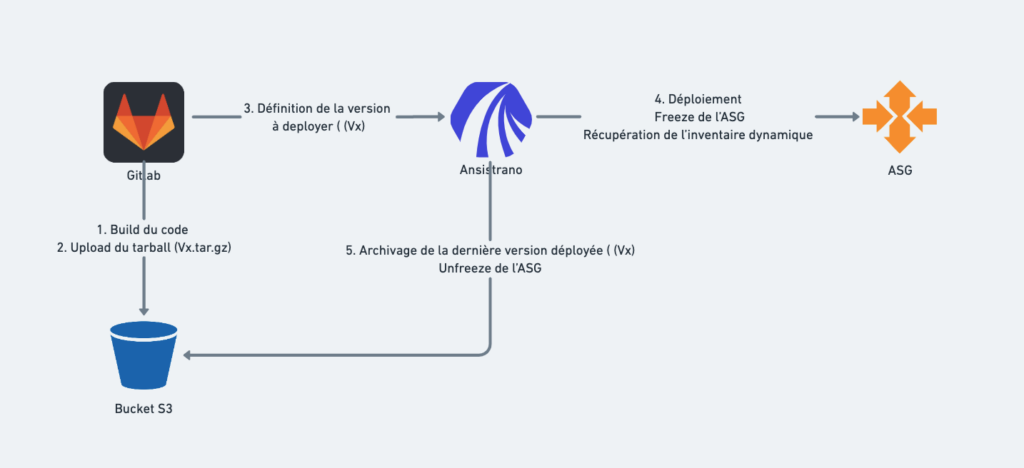
Déploiement
- Freeze de l’autoscaling
- Récupération de l’inventaire dynamique
- Récupération de la version à déployer dans le fichier de RELEASE
- Pull du build depuis le S3
- Lancement des tâches de déploiement classiques (cache, upgrade db)
- Unfreeze de l’autoscaling
Upscalling
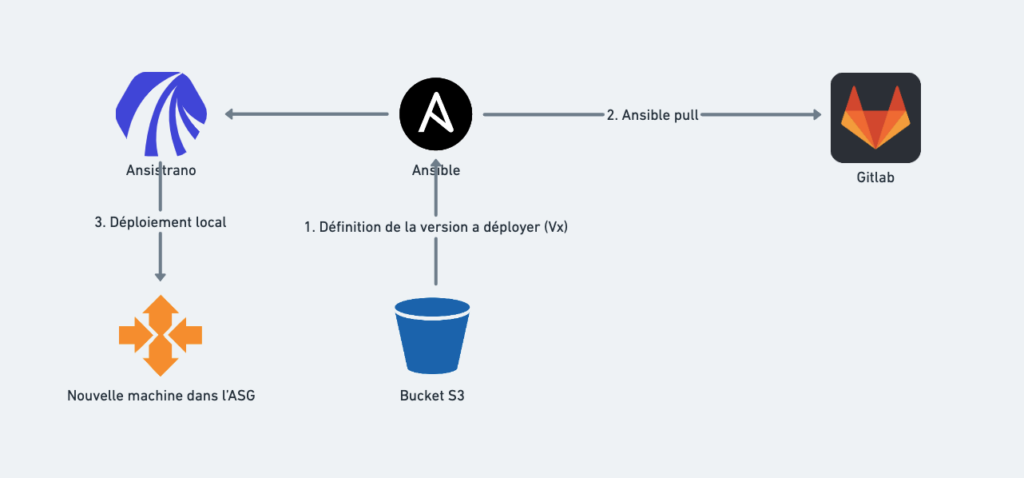
Lorsqu’une nouvelle instance est créée sur l’ASG, le serveur est automatiquement installé, mais il est « brut » c’est-à-dire sans l’applicatif.
Pour déployer celui-ci, un script de provisonning va utiliser notre dépôt Ansistrano avec une commande de ce type :
ansible-pull deploy.yml --url ssh://git@git.com/ansible.gitCe script exécute les tâches de déploiement également utilisées dans la CI, mais avec en host uniquement « localhost ».
- Récupération de la version à déployer dans le fichier de RELEASE
- Récupération du build (tarball) depuis le S3
- Lancement des tâches de déploiement classiques (cache, upgrade db)
Gitlab CI
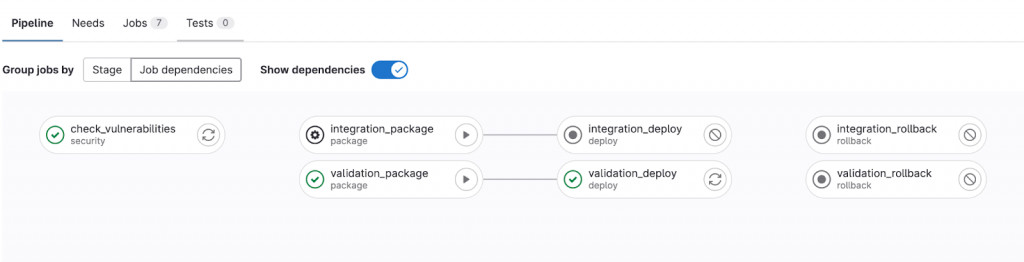
Pour la gestion du build et de tout le pipeline de publication, de version et déploiement, j’ai utilisé notre gitlab-ci et un runner dédié sur l’infra VPC AWS.
Voici un exemple de Pipeline avec deux environnements sur la même branche.
Le résultat
Cette solution a plusieurs avantages. La séparation du code et du déploiement dans deux dépôts distincts permet d’avoir uniquement du code « ready to prod » sur le serveur et de provisionner un serveur avec l’applicatif sans pull tout le dépôt de code comme pourrait le faire Capistrano à chaque déploiement.